Gists

Abstract
This report investigates how Gemini handles current time information, particularly when using the Gemini API. We found that while the Gemini web interface knows the current time, the Gemini API does not inherently. Therefore, applications must explicitly provide current time information in API calls for accurate time-sensitive responses.
Introduction
The rapidly advancing field of generative AI is enabling increasingly complex tasks, particularly through the use of open protocols like the Model Context Protocol (MCP) and Agent2Agent (A2A) Protocol. These protocols facilitate sophisticated operations that often require accurate and dynamic information, including time-sensitive data. For instance, applications that manage schedules or coordinate events critically depend on precise time information.
Gists
Abstract
This report details transferring image data via Model Context Protocol (MCP) from Google Apps Script server to a Python/Gemini client, extending capabilities for multimodal applications beyond text.
Introduction
Following up on my previous report, “Building Model Context Protocol (MCP) Server with Google Apps Script” (Ref), which detailed the transfer of text data between the MCP server and client, this new report focuses on extending the protocol to handle image data. It introduces a practical method for transferring image data efficiently from the Google Apps Script-based MCP server to an MCP client. In this implementation, the MCP client was built using Python and integrated with the Gemini model, allowing for the processing and utilization of the transferred image data alongside text, thereby enabling more complex, multimodal applications within the MCP framework.
Gists

Abstract
The report details a novel Gemini API method to analyze big data beyond AI context window limits, which was validated with Stack Overflow data for insights into Google Apps Script’s potential.
Introduction
Generative AI models face significant limitations when processing massive datasets, primarily due to the constraints imposed by their fixed context windows. Current methods thus struggle to analyze the entirety of big data within a single API call, preventing comprehensive analysis. To address this challenge, I have developed and published a detailed report presenting a novel approach using the Gemini API for comprehensive big data analysis, designed to operate effectively beyond typical model context window limits. Ref
Gists

Abstract
Generative AI faces limits in processing massive datasets due to context windows. Current methods can’t analyze entire data lakes. This report presents a Gemini API approach for comprehensive big data analysis beyond typical model limits.
Introduction
The rapid advancement and widespread adoption of generative AI have been remarkable. High expectations are placed on these technologies, particularly regarding processing speed and the capacity to handle vast amounts of data. While AI processing speed continues to increase with technological progress, effectively managing and analyzing truly large datasets presents significant challenges. The current practical limits on the amount of data that can be processed or held within a model’s context window simultaneously, sometimes around a million tokens or less, depending on the model and task, restrict direct comprehensive analysis of massive data lakes.
Gists

Abstract
Gemini 2.5 Pro Experimental enabled automated cargo ship stowage planning via prompt engineering, overcoming prior model limitations. This eliminates the need for complex algorithms, demonstrating AI’s potential in logistics.
Introduction
Recently, I encountered a practical business challenge: automating stowage planning through AI. Specifically, I received a request to generate optimal container loading plans for cargo ships, a task traditionally requiring significant manual effort and domain expertise. In initial tests, prior to the release of Gemini 2.5, I found that existing models struggled to effectively handle the complexities of this problem, including constraints like weight distribution, container dimensions, and destination sequencing. However, with the release of Gemini 2.5, I observed a significant improvement in the model’s capabilities. Utilizing the Gemini 2.5 Pro Experimental model, I successfully demonstrated the generation of viable stowage plans using only carefully crafted prompts. This breakthrough eliminates the need for complex, custom-built algorithms or extensive training datasets. The successful implementation involved providing the model with key parameters such as container dimensions, weights, destination ports, and ship capacity. This report details the methodology, prompt engineering, and results of my attempt to create automated stowage planning using Gemini 2.5 Pro Experimental, highlighting its potential to revolutionize logistics and shipping operations.
Gists
Abstract
This research explores “pseudo function calling” in Gemini API using prompt engineering with JSON schema, bypassing model dependency limitations.
Introduction
Large Language Models (LLMs) like Gemini and ChatGPT offer powerful functionalities, but their capabilities can be further extended through function calling. This feature allows the LLM to execute pre-defined functions with arguments generated based on the user’s prompt. This unlocks a wide range of applications, as demonstrated in these resources (see References).
Gists
Overview
These are sample scripts in Python and Node.js for controlling the output format of the Gemini API using JSON schemas.
Description
In a previous report, “Taming the Wild Output: Effective Control of Gemini API Response Formats with response_mime_type,” I presented sample scripts created with Google Apps Script. Ref Following its publication, I received requests for sample scripts using Python and Node.js. This report addresses those requests by providing sample scripts in both languages.
Gists

Abstract
The Gemini API unlocks potential for diverse applications but requires consistent output formatting. This report proposes a method using question phrasing and API calls to craft a bespoke output, enabling seamless integration with user applications. Examples include data categorization and obtaining multiple response options.
Introduction
With the release of the LLM model Gemini as an API on Vertex AI and Google AI Studio, a world of possibilities has opened up. Ref The Gemini API significantly expands the potential of various scripting languages and paves the way for diverse applications. However, leveraging the Gemini API smoothly requires consistent output formatting, which can be tricky due to its dependence on the specific question asked.
Gists

Abstract
One day, you might have a situation where it is required to run Google Apps Script using the service account. Unfortunately, in the current stage, Google Apps Script cannot be directly run with the service account because of the current specification. So, this report introduces a workaround for executing Google Apps Script using the service account.
Introduction
When you want to execute Google Apps Script from outside of Google, as the basic approach, it can be achieved by Google Apps Script API. Ref In order to use Google Apps Script, it is required to link the Google Apps Script project with the Google Cloud Platform project. Ref But, in the current stage, Google Apps Script can be executed by Google Apps Script API with only the access token obtained from OAuth2. Unfortunately, the access token obtained by the service account cannot used for executing Google Apps Script using Google Apps Script API. It seems that this is the current specification on the Google side. However, there might be a case that it is required to execute Google Apps Script using the service account. In this report, I would like to introduce a workaround for executing Google Apps Script using the service account. In this workaround, the Web Apps created by Google Apps Script is used. The Web Apps can be used for executing the preserved functions of doGet and doPost from outside of Google. Ref In this workaround, this Web Apps is used for executing the various functions.
Gists
This is a sample script for achieving the resumable download of a file from Google Drive using Dive API with Python.
There might be a case in that you want to achieve the resumable download of a file from Google Drive using Dive API with Python. For example, when a large file is downloaded, the downloading might be stopped in the middle of downloading. At that time, you might want to resume the download. In this post, I would like to introduce the sample script of python.
Gists
When Google APIs are used with googleapis for Python, the client is obtained as follows.
creds = service_account.Credentials.from_service_account_file(service_account_credential_file, scopes=scopes)
service = build("drive", "v3", credentials=creds)
In this case, when the script is run, the access token is retrieved every time. But, the expiration time of the retrieved access token is 1 hour. Here, there might be the case that you want to use the access token until the expiration time. It is considered that effectively using the access token will lead to SDGs. In this post, I would like to introduce a sample script for using the access token until the expiration time.
Gists
This is a sample script for retrieving the access token from the service account using oauth2client and google-auth with Python.
Sample script 1
Use oauth2client.
from oauth2client.service_account import ServiceAccountCredentials
SERVICE_ACCOUNT_FILE = "credentials.json"
SCOPES = ["https://www.googleapis.com/auth/drive"]
creds = ServiceAccountCredentials.from_json_keyfile_name(SERVICE_ACCOUNT_FILE, scopes=SCOPES)
res = creds.get_access_token()
access_token = res.access_token
print(access_token)
Sample script 2
Use google-auth. In the current stage, this method might be general.
from google.oauth2 import service_account
import google.auth.transport.requests
SERVICE_ACCOUNT_FILE = "credentials.json"
SCOPES = ["https://www.googleapis.com/auth/drive"]
creds = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_FILE, scopes=SCOPES)
request = google.auth.transport.requests.Request()
creds.refresh(request)
access_token = creds.token
print(access_token)
References
Gists
This is a sample script for uploading files to Google Drive with asynchronous process using Python.
Sample script
import aiohttp
import asyncio
import json
folder_id = "###" # Please set the folder ID you want to put.
token = "###" # Please set your access token.
url = "https://www.googleapis.com/upload/drive/v3/files"
async def workers(file):
async with aiohttp.ClientSession() as session:
metadata = {"name": file["filename"], "parents": [folder_id]}
data = aiohttp.FormData()
data.add_field("metadata", json.dumps(metadata), content_type="application/json; charset=UTF-8")
data.add_field("file", open(file["path"], "rb"))
headers = {"Authorization": "Bearer " + token}
params = {"uploadType": "multipart"}
async with session.post(url, data=data, params=params, headers=headers) as resp:
return await resp.json()
async def main():
# Please set the filenames and the file paths as follows.
fileList = [
{"filename": "sample1", "path": "./sample1.png"},
,
,
,
]
works = [asyncio.create_task(workers(e)) for e in fileList]
res = await asyncio.gather(*works)
print(res)
asyncio.run(main())
- When this script is run, the files of
fileList are uploaded to Google Drive with the asynchronous process.
Note
- This sample supposes that your access token can be used for uploading files to Google Drive using Drive API. Please be careful about this.
Reference
Gists
This is a sample script for replacing the template texts with an array in Google Document using Docs API with Python.
The sample input and output situations are as follows.
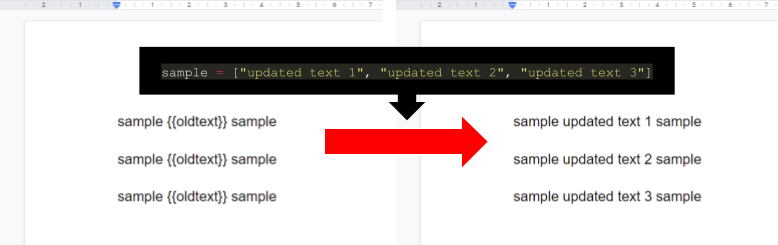
In the current stage, when replaceAllText of Docs API is used with the sample value of ["updated text 1", "updated text 2", "updated text 3"], all values of {{oldText}} are replaced with the 1st value of updated text 1 in one batch request. So in order to replace each {{oldText}} with ["updated text 1", "updated text 2", "updated text 3"], it is required to use a workaround.
Gists
This is the sample scripts for creating new event with Google Meet link to Google Calendar using various languages. When I saw the official document of “Add video and phone conferences to events”, in the current stage, I can see only the sample script for Javascript. But I saw the several questions related to this for various languages. So I published the sample scripts for creating new event with Google Meet link to Google Calendar using various languages.
Gists
This is a sample script for retrieving all values from all sheets from URL of 2PACX- of Web Published Google Spreadsheet using Python.
In this post, it supposes that the Google Spreadsheet has already been published for Web. Ref
Flow
The flow of this method is as follows.
- Retrieve XLSX data from the URL of web published Google Spreadsheet as
BytesIO data.
- The URL is like
https://docs.google.com/spreadsheets/d/e/2PACX-###/pubhtml.
- XLSX data is parsed with openpyxl.
- Retrieve all values from all sheets.
Sample script
Please set spreadsheetUrl.
python library - getfilelistpy was updated to v1.0.7.
You can check getfilelistpy at https://github.com/tanaikech/getfilelistpy.
You can also check getfilelistpy at https://pypi.org/project/getfilelistpy/.
Updated: GetFileList for golang, Javascript, Node.js and Python
This is the libraries to retrieve the file list with the folder tree from the specific folder of own Google Drive and shared Drives.
python library - getfilelistpy was updated to v1.0.5.
-
v1.0.5 (May 15, 2020)
-
Shared drive got to be able to be used. The file list can be retrieved from both your Google Drive and the shared drive.
- For example, when the folder ID in the shared Drive is used
id of resource, you can retrieve the file list from the folder in the shared Drive.
You can check getfilelistpy at https://github.com/tanaikech/getfilelistpy.
You can also check getfilelistpy at https://pypi.org/project/getfilelistpy/.
Gists
This is a simple sample script for achieving the resumable upload to Google Drive using Python. In order to achieve the resumable upload, at first, it is required to retrieve the location, which is the endpoint of upload. The location is included in the response headers. After the location was retrieved, the file can be uploaded to the location URL.
In this sample, a PNG file is uploaded with the resumable upload using a single chunk.
Libraries of gdoctableapp for golang, Node.js and python were updated to v1.1.0
Libraries of gdoctableapp for golang, Node.js and python were updated to v1.0.5
Update History
python library - getfilelistpy was updated to v1.0.4.
-
v1.0.4 (August 23, 2019)
- For OAuth2,
oauth2client and google_auth_oauthlib got to be able to be used. About the sample script for google_auth_oauthlib, please see this.
You can check getfilelistpy at https://github.com/tanaikech/getfilelistpy.
You can also check getfilelistpy at https://pypi.org/project/getfilelistpy/.
Gists
This is a sample script for creating a table to Google Document by retrieving values from Google Spreadsheet for Python.
Before you use this script, please install python library of gdoctableapppy.
$ pip install gdoctableapppy
Sample script:
This sample script uses Service Account.
In this sample script, the values are retrieved from Sheet1!A1:C5 of Spreadsheet, and new table is created to the Document using the values.
from google.oauth2 import service_account
from gdoctableapppy import gdoctableapp
from googleapiclient.discovery import build
SCOPES = ['https://www.googleapis.com/auth/documents',
'https://www.googleapis.com/auth/spreadsheets']
SERVICE_ACCOUNT_FILE = 'credential.json' # Please set the json file of Service account.
creds = service_account.Credentials.from_service_account_file(
SERVICE_ACCOUNT_FILE, scopes=SCOPES)
service = build('sheets', 'v4', credentials=creds)
spreadsheet_id = '###' # Please set here
document_id = '###' # Please set here
res = service.spreadsheets().values().get(
spreadsheetId=spreadsheet_id, range='Sheet1!A1:C5').execute()
values = res['values']
resource = {
"service_account": creds,
"documentId": document_id,
"rows": len(values),
"columns": len(values[0]),
"append": True,
"values": values
}
res = gdoctableapp.CreateTable(resource)
print(res)
References:
Overview
This is a python library to manage the tables on Google Document using Google Docs API.
Description
Google Docs API has been released. When I used this API, I found that it is very difficult for me to manage the tables on Google Document using Google Docs API. Although I checked the official document, unfortunately, I thought that it’s very difficult for me. So in order to easily manage the tables on Google Document, I created this library.
Overview
This is a python library to retrieve the file list with the folder tree from the specific folder of Google Drive.
Description
When I create applications for using Google Drive, I often retrieve a file list from a folder in the application. So far, I had created the script for retrieving a file list from a folder for each application. Recently, I thought that if there is the script for retrieving the file list with the folder tree from the folder of Google Drive as a library, it will be useful for me and other users. So I created this.
Gists
This is a sample script for uploading files from local PC to Google Drive using Python. In this sample, Quickstart is not used. So when you use this script, please retrieve access token.
Curl sample :
curl -X POST \
-H "Authorization: Bearer ### access token ###" \
-F "metadata={name : 'sample.png', parents: ['### folder ID ###']};type=application/json;charset=UTF-8" \
-F "file=@sample.png;type=image/png" \
"https://www.googleapis.com/upload/drive/v3/files?uploadType=multipart"
]
Python sample :
When above curl sample is converted to Python, it becomes as follows.
Gist
This is a sample script for decoding Gmail body with Japanese language using Python.
msg = service.users().messages().get(userId='me', id=id).execute()
parts = msg['payload']['parts']
for e in parts:
msg = base64.urlsafe_b64decode(e['body']['data']).decode('utf-8').encode('cp932', "ignore").decode('cp932')
print(msg)
Gists
This sample script is for updating thumbnail of file on Google Drive using Python.
This sample supposes that quickstart is used and default quickstart works fine. In order to use this sample, please carry out as follows.
- Replace
main() of the default quickstart to this sample.
Script :
import base64 # This is used for this sample.
def main():
credentials = get_credentials()
http = credentials.authorize(httplib2.Http())
service = discovery.build('drive', 'v3', http=http)
with open("./sample.png", "rb") as f:
res = service.files().update(
fileId="### file ID ###",
body={
"contentHints": {
"thumbnail": {
"image": base64.urlsafe_b64encode(f.read()).decode('utf8'),
"mimeType": "image/png",
}
}
},
).execute()
print(res)
contentHints.thumbnail.image is URL-safe Base64-encoded image. So an image data that you want to use as new thumbnail has to be converted to URL-safe Base64-encoded data. For this, it uses base64.urlsafe_b64encode() at Python.
This sample is for error handling for subprocess.Popen. It confirms whether the execution file is existing. If the execution file is also not in the path, the error message is shown.
import subprocess
res = subprocess.Popen(
"application", # <- Execution file
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True
).communicate()
if len(res[1]) == 0:
print("ok: Application is existing.")
else:
print("Error: Application is not found.")
This sample is for using constructor between classes at Python.
Sample :
class test1:
def __init__(self):
self.msg = "sample text"
class test2:
def __init__(self):
self.msg = test1().msg
print(test2().msg)
>>> sample text
This “souwapy” is a library for summing array elements with high speed by new algorithm (Pyramid method). The speed is faster than csv and panbdas module of python and v8 engine of node.js. The souwapy module is 2.3 and 3.1 times faster than csv and pandas module, respectively. This was really surprised me. It was found that the theory was correct.
At first, I have created this theory for Google Apps Script. But recently I had to use large data and output a csv file on python. So I made this library. Additionally, I had wanted to know how to public own library to PyPI before. This chance was good for me. If this library is helpful for other people, I’m glad.
Suddenly I had to need this.
This script can get the duplicate number of each element in array at Python. In this script, the duplicate number of each element is obtained and sorted by the duplicate number. This was expressed by the comprehension.
data = ['a', 'b', 'c', 'd', 'b', 'c', 'd', 'b', 'c', 'b']
result = sorted({i: data.count(i) for i in set(data)}.items(), key=lambda x: x[1], reverse=True)
print(result)
>>> [('b', 4), ('c', 3), ('d', 2), ('a', 1)]