
Abstract
The report details a novel Gemini API method to analyze big data beyond AI context window limits, which was validated with Stack Overflow data for insights into Google Apps Script’s potential.
Introduction
Generative AI models face significant limitations when processing massive datasets, primarily due to the constraints imposed by their fixed context windows. Current methods thus struggle to analyze the entirety of big data within a single API call, preventing comprehensive analysis. To address this challenge, I have developed and published a detailed report presenting a novel approach using the Gemini API for comprehensive big data analysis, designed to operate effectively beyond typical model context window limits. Ref
This report introduces and validates the results achieved by applying this Gemini API approach to a substantial real-world dataset. The dataset analyzed comprises questions, answers, and comments retrieved directly from Stack Overflow, demonstrating the method’s applicability to large-scale, complex textual data. The analysis results provide insights into the current situation and future potential of Google Apps Script.
Workflow
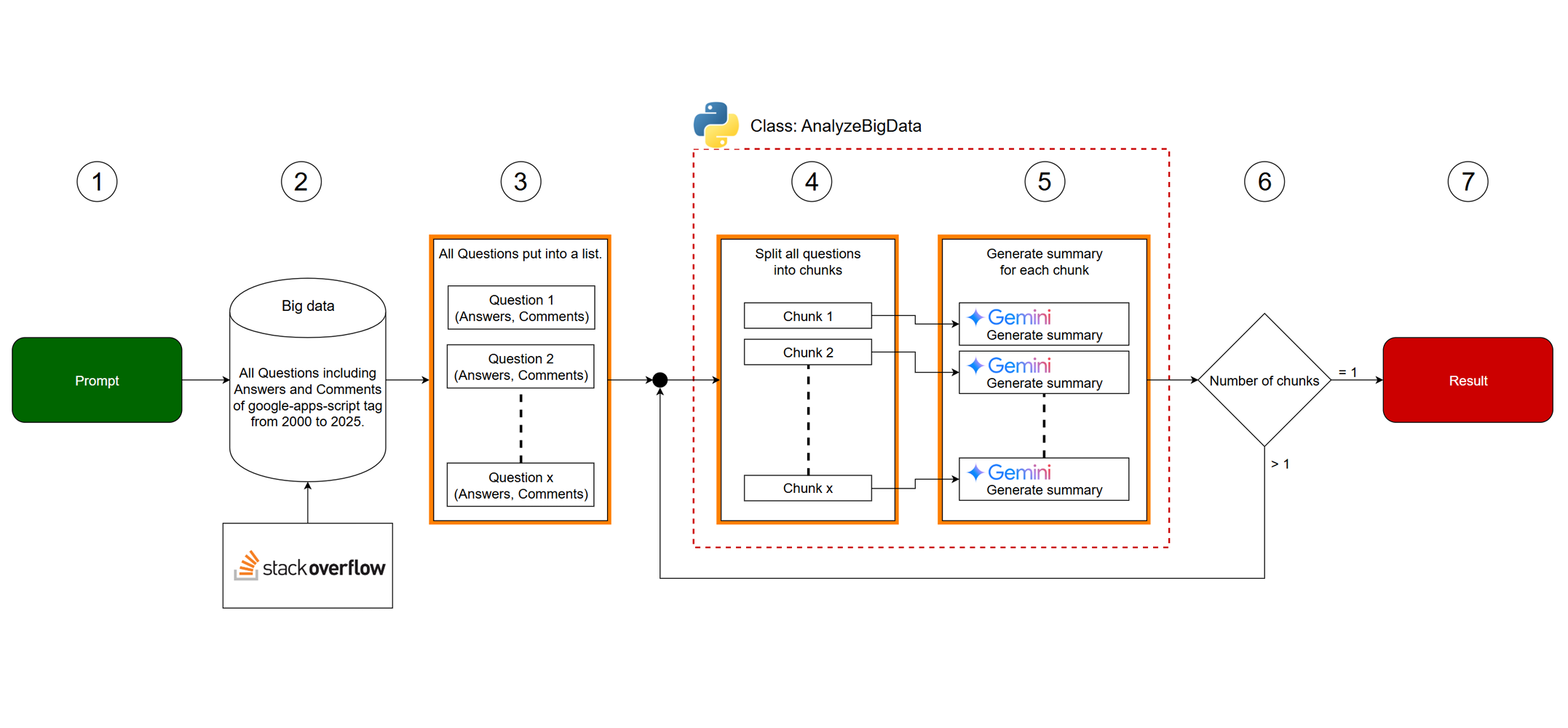
The above workflow image is described as follows:
- An initial Input prompt is provided.
- Big data is retrieved from Stack Overflow.
- The retrieved big data is split into individual Questions including Answers and Comments. These are then organized into a list.
- Inside Class AnalyzeBigData, the data is split into chunks. Each chunk’s token count is kept below the input token limitation of the Gemini API.
- Generate a summary for each chunk using the given prompt. This step utilizes Gemini to process each chunk.
- If the Number of chunks is greater than 1, the generated summaries are processed again by the
AnalyzeBigDataclass. This indicates a recursive or iterative process. - If the number of chunks is 1, the final result is returned. This is the termination condition for the process.
Big data
The data for this report was sourced from Stack Overflow, specifically focusing on the google-apps-script tag. Utilizing the StackExchange API, a comprehensive dataset was retrieved, encompassing all questions posted within the specified timeframe, alongside all associated answers and comments. The data collection included essential metadata for each post, such as creation date, score, view count, and relationships between questions, answers, and comments.
The chosen timeframe for data retrieval is from January 1, 2020, through April 24, 2025. This period was selected to align with ongoing annual trend analysis and to specifically investigate recent shifts in community activity. As previously documented in reports such as “Trend of google-apps-script Tag on Stackoverflow 2025”, Fig. 1 illustrates a decrease in the number of new questions tagged google-apps-script in recent years. This decline is understood to be significantly influenced by the increasing use of AI tools for coding assistance. Therefore, collecting data from 2020 allows for an analysis that covers the period leading up to and during the more prominent rise of AI tools, enabling a focused examination of their potential impact on the google-apps-script community on Stack Overflow and providing insights into the future trajectory of this technology under these changing circumstances.
The data for all questions from 2020 to April 24, 2025, on Stack Overflow is as follows.
- Number of questions: 27,432
- Number of answers: 29,208
- Number of comments to questions: 64,713
- Number of comments to answers: 47,413
- Total data size: 127,106,040 bytes
Script
In this case, in order to obtain the final result, I used the following 2 scripts.
- The original JSON data was split into chunks, and JSON data was generated from each chunk.
- A summary was generated from the generated JSON data.
When you test these scripts, first, please get analyze_big_data_by_Gemini.py from my repository. https://github.com/tanaikech/analyze_big_data_by_Gemini
Also, before you test these scripts, it is required to retrieve the data from Stackoverflow. The JSON schema of the data can be seen at “json_schema” of “Script 1”.
Script 1
In this script, the big data retrieved from Stackoverflow is split into chunks, and the summaries are generated from each chunk. And, the result is saved as a file generated_contents.txt.
In this case, both the start and end data are JSON data.
from analyze_big_data_by_Gemini import AnalyzeBigData
import json
import os
api_key = "###" # Your API key.
filename = "sample_data_file.txt"
file_path = os.path.join("./", filename)
data = []
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
data = json.loads(content)
json_schema = {
"title": "Stack Overflow Data Schema",
"description": "Schema for Stack Overflow question and answer data",
"type": "array",
"items": {
"type": "object",
"properties": {
"data": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "Title of the Stack Overflow question",
},
"link": {
"type": "string",
"format": "url",
"description": "Link to the Stack Overflow question",
},
"date": {
"type": "string",
"format": "date-time",
"description": "Date and time the question was posted",
},
"question": {
"type": "string",
"description": "Content of the Stack Overflow question. This is a markdown format.",
},
"comments": {
"type": "array",
"description": "Comments on the question",
"items": {"type": "string"},
},
"answers": {
"type": "array",
"description": "Answers to the question",
"items": {
"type": "object",
"properties": {
"date": {
"type": "string",
"format": "date-time",
"description": "Date and time the answer was posted",
},
"is_accepted": {
"type": "boolean",
"description": "Indicates if the answer is accepted",
},
"answer": {
"type": "string",
"description": "Content of the answer. This is a markdown format.",
},
"comments": {
"type": "array",
"description": "Comments on the answer. This is a markdown format.",
"items": {"type": "string"},
},
},
"required": [
"date",
"is_accepted",
"answer",
"comments",
],
},
},
},
"required": [
"title",
"link",
"date",
"question",
"comments",
"answers",
],
},
}
},
"required": ["data"],
},
}
prompt = [
"There is JSON data in the uploaded file of the attachment. This JSON data is retrieved from Stackoverflow.",
"The JSON schema of the JSON data is JSONSchema.",
f"<JSONSchema>${json.dumps(json_schema)}</JSONSchema>",
"Understand the given whole data, including questions, answers to each question, comments to each question, and comments to each answer, and summarize it to investigate a trend of Google Apps Script.",
"<IncludePoints>",
"- Relationship between Google Apps Script and AI.",
"- Activity of users with Google Apps Script on Stackoverflow.",
"- Highly interested in fields with Google Apps Script.",
"- The reason why the number of questions and answers decreases every year after 2020.",
"- Future potential of Google Apps Script.",
"- Future challenges of Google Apps Script.",
"- Strategy for increasing the users of Google Apps Script on Stackoverflow.",
"- Future role of Stackoverflow to the users of Google Apps Script.",
"</IncludePoints>",
"Include the above points in the property of 'content' in the response schema.",
]
response_schema = {
"description": "JSON schema for the generated content.",
"type": "array",
"items": {
"type": "object",
"properties": {
"date": {
"type": "object",
"properties": {
"start": {
"type": "string",
"description": "Start date of the question in the data.",
},
"end": {
"type": "string",
"description": "End date of the question in the data.",
},
},
"required": ["start", "end"],
},
"content": {"type": "string", "description": "Generated summary."},
},
"required": ["date", "content"],
},
}
object = {
"api_key": api_key,
"data": data,
"prompt": "\n".join(prompt),
"response_mime_type": "application/json",
"response_schema": response_schema,
}
res = AnalyzeBigData().run(object)
with open("./generated_contents.txt", "w", encoding="utf-8") as f:
json.dump(res, f, indent=2)
Script 2
In this script, the file generated_contents.txt created by “Sample 1” is split into chunks, and a summary is generated from all chunks. And, the result is saved as a file result.txt. This is the final result.
In this case, the start and end data are JSON data and text data, respectively.
from analyze_big_data_by_Gemini import AnalyzeBigData
import json
import os
api_key = "###" # Your API key.
filename = "generated_contents.txt"
file_path = os.path.join("./", filename)
data = []
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
data = json.loads(content)
json_schema = {
"description": "JSON schema for the generated content.",
"type": "array",
"items": {
"type": "object",
"properties": {
"date": {
"type": "object",
"properties": {
"start": {
"type": "string",
"description": "Start date of the question in the data.",
},
"end": {
"type": "string",
"description": "End date of the question in the data.",
},
},
"required": ["start", "end"],
},
"content": {"type": "string", "description": "Generated summary."},
},
"required": ["date", "content"],
},
}
prompt = [
"There is JSON data in the uploaded file of the attachment. This JSON data is retrieved from Stackoverflow.",
"The JSON schema of the JSON data is JSONSchema.",
f"<JSONSchema>${json.dumps(json_schema)}</JSONSchema>",
"Understand the given whole data, including questions, answers to each question, comments to each question, and comments to each answer, and summarize it to investigate a trend of Google Apps Script.",
"<IncludePoints>",
"- Relationship between Google Apps Script and AI.",
"- Activity of users with Google Apps Script on Stackoverflow.",
"- Highly interested in fields with Google Apps Script.",
"- The reason why the number of questions and answers decreases every year after 2020.",
"- Future potential of Google Apps Script.",
"- Future challenges of Google Apps Script.",
"- Strategy for increasing the users of Google Apps Script on Stackoverflow.",
"- Future role of Stackoverflow to the users of Google Apps Script.",
"</IncludePoints>",
"Include the above points in the result.",
]
object = {
"api_key": api_key,
"data": data,
"prompt": "\n".join(prompt),
"limit_length": 1000000,
}
res = AnalyzeBigData().run(object)
if len(res) == 1:
with open("./result.txt", "w", encoding="utf-8") as f:
f.write(res[0])
Result
When the summary is generated from this big data with the above workflow using these 2 scripts, the following result was obtained. It’s content in the file result.txt. You can see that the questions related to Google Apps Script from January 1, 2020, to April 24, 2025, are reflected in the result.
Generated summary
-
Current Usage Patterns and Interests Based on Stack Overflow data (Jan 2020 - Apr 2025), Google Apps Script users are highly active in automating Google Workspace. Key interests include extensive data manipulation in Google Sheets (triggers, formulas, large datasets), integration with Drive, Gmail, Forms, and Calendar, building custom UIs (HTML Service), and connecting to external APIs via
UrlFetchApp. Authentication and data parsing challenges are common when integrating with APIs. -
Common Programming Challenges Users frequently face typical Apps Script programming difficulties such as debugging errors (permissions, timeouts, cryptic API responses), managing data structures, handling asynchronous operations, and performance optimization (batching, avoiding row-by-row updates, hitting quotas). Persistent hurdles include understanding permissions and authorization for triggers and Web Apps, along with the reliability and specific behavior of triggers.
-
Reasons for Decreased Stack Overflow Activity The observed decline in Apps Script questions on Stack Overflow after 2020 is likely due to platform maturity providing existing solutions, the rise of alternative low-code/no-code tools (like AppSheet) or other cloud environments (like Cloud Functions) absorbing some use cases, and user frustration with debugging, performance limits, API inconsistencies, and platform quirks leading some to seek help elsewhere.
-
Impact of AI Code Generation Increasingly, users leverage AI tools (ChatGPT, Bard, Gemini) for generating initial script code and debugging assistance. This reduces the volume of basic coding questions asked on Stack Overflow. However, users still turn to the platform for help debugging AI-generated code that doesn’t work or for more complex or nuanced problems requiring human expertise.
-
Future Potential of Google Apps Script Google Apps Script holds strong future potential because of its deep integration with the widely used Google Workspace suite. It remains a uniquely powerful and accessible tool for automating workflows, customizing applications, building internal tools, and connecting Google services with each other and external platforms. Its future could also involve acting as an integration layer for Google Cloud capabilities, including AI/ML services.
-
Key Future Challenges Future challenges for Google Apps Script include improving performance for large-scale operations, simplifying the complex permission and authorization models, enhancing debugging tools across various execution contexts, improving API consistency, providing clearer guidance for integration with modern web practices and complex external services, and adapting to how developers use AI for script generation.
-
Strategies for Increased Stack Overflow Engagement To potentially boost Stack Overflow activity, strategies could focus on Google promoting SO as the primary community support channel, improving the discoverability of existing high-quality answers for common complex problems (performance, permissions), encouraging minimal reproducible examples (MCVEs) for better problem-solving, fostering community discussion on advanced topics and workarounds, and creating curated content specifically addressing debugging AI-generated Apps Script code.
-
Future Role of Stack Overflow Stack Overflow’s future role for Google Apps Script users will likely continue as a critical, community-driven knowledge base. It will be essential for troubleshooting specific coding errors, finding practical code examples, understanding nuanced API behaviors, discovering workarounds for platform limitations, and sharing best practices. As AI handles more basic tasks, SO’s value will shift towards solving complex, unique, or difficult-to-debug problems requiring human collaboration.
-
Apps Script and AI Relationship Dynamics The data shows AI (like ChatGPT, Gemini) primarily influences Apps Script usage by assisting developers with code generation and debugging. While integrating AI services into Apps Script is possible but less common, the use of AI as a coding assistant is growing. This trend is likely shifting the types of questions on Stack Overflow towards debugging AI-generated code or tackling more complex integration challenges.
Summary
- A novel Gemini API method was developed to analyze big data beyond context window limits.
- This method was applied to questions related to Google Apps Script retrieved from Stack Overflow (2020-2025).
- The analysis revealed decreased Stack Overflow activity, influenced by AI code generation tools.
- Findings detailed current usage, common challenges, and future potential of Google Apps Script.