Abstract
New “semantic search” features in Gemini API help find desired information within its corpora. While using these features with Google Apps Script was complex, a new library simplifies the process. This report proposes using this library with Gemini-generated content to automate template processes in Google Docs and Slides, creating a more flexible workflow.
Introduction
The semantic search opens up a new wind for finding the expected values. Recently, the APIs for managing corpora have been added to Gemini API. Ref When the corpora of Gemini API is used, the semantic search can be effectively achieved. Ref However, when the corpora are tried to be used with Google Apps Script, the script is complicated cumbersome. To address this challenge, I have created a library for managing the corpora using Google Apps Script. Ref With this library, managing corpora becomes effortless, requiring only straightforward scripts.
In this report, I would like to apply the semantic search with the corpora and the generated content of Gemini API to the template process using Google Documents and Google Slides. By this, it achieves the flexible template process.
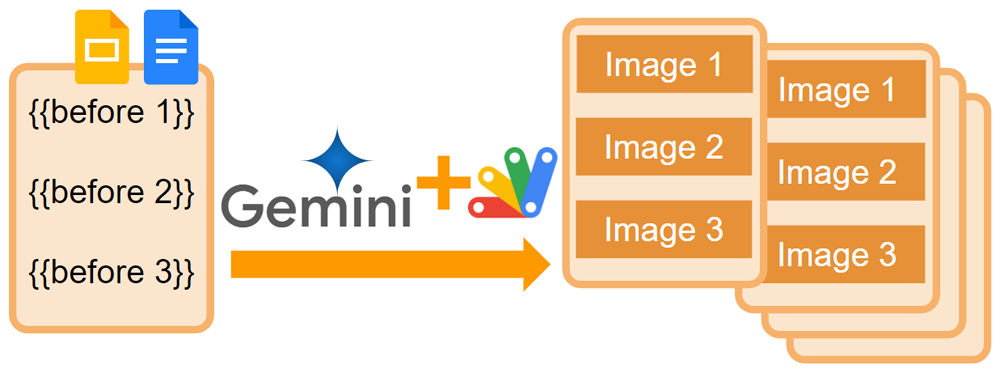
Flow for achieving the flexible template process
In order to achieve the flexible template process using the semantic search, the following flow is used. In this report, the images are put using the templates.
- Prepare images. Please put the images into a folder on your Google Drive.
- Create descriptions of images using the generated content of Gemini API.
- Create a corpus.
- Create a document in the corpus.
- Store the created description in the document by including the file metadata.
- Run the template process using the semantic search using the document including the data.
I prepared the sample images by generating them with Bard as follows.
Usage
In order to test the following scripts, please do the following flow.
1. Create a Google Apps Script project
Please create a standalone Google Apps Script project. Of course, this script can be also used with the container-bound script.
And, please open the script editor of the Google Apps Script project.
2. Linking Google Cloud Platform Project to Google Apps Script Project for New IDE
In this case, you can see how to do this at my repository.
Also, please enable Generative Language API at the API console.
3. Install a Google Apps Script library (CorporaApp)
You can see how to install this library at here.
By this flow, the preparation for using the following scripts was finished.
Store data in the corpus
Before the template process, it is required to store the data in the document in a corpus. The script for this is as follows.
In this sample, the images are used. So, please prepare some images in a folder in your Google Drive.
Please copy and paste the following script to the script editor. Please set the folder ID of the folder including images to folderId of the function main.
const createCorpus_ = (_) =>
CorporaApp.createCorpus({
name: "corpora/sample-corpus",
displayName: "sample corpus",
});
const createDocument_ = (_) =>
CorporaApp.createDocument("corpora/sample-corpus", {
name: "corpora/sample-corpus/documents/sample-document",
displayName: "sample document",
});
/**
* ### Description
* Generate text from text and image.
* ref: https://medium.com/google-cloud/automatically-creating-descriptions-of-files-on-google-drive-using-gemini-pro-api-with-google-apps-7ef597a5b9fb
*
* @param {Object} object Object including API key, text, mimeType, and image data.
* @return {String} Generated text.
*/
function getResFromImage_(object) {
const { token, text, mime_type, data } = object;
const url = `https://generativelanguage.googleapis.com/v1/models/gemini-pro-vision:generateContent`;
const payload = {
contents: [{ parts: [{ text }, { inline_data: { mime_type, data } }] }],
};
const options = {
payload: JSON.stringify(payload),
contentType: "application/json",
headers: { authorization: "Bearer " + token },
};
const res = UrlFetchApp.fetch(url, options);
const obj = JSON.parse(res.getContentText());
if (obj.candidates.length > 0 && obj.candidates[0].content.parts.length > 0) {
return obj.candidates[0].content.parts[0].text;
}
return "No response.";
}
// Please run this function.
function main() {
const folderId = "###"; // Please set the folder ID of the folder including images.
const documentResourceName =
"corpora/sample-corpus/documents/sample-document";
createCorpus_(); // Create corpus as "corpora/sample-corpus".
createDocument_(); // Create document into the corpus as "corpora/sample-corpus/documents/sample-document".
// 1. Retrieve description of the images using Gemini API.
const requests = [];
const files = DriveApp.getFolderById(folderId).searchFiles(
"trashed=false and mimeType contains 'image/'"
);
const token = ScriptApp.getOAuthToken();
while (files.hasNext()) {
const file = files.next();
const fileId = file.getId();
const url = `https://drive.google.com/thumbnail?sz=w1000&id=${fileId}`;
const bytes = UrlFetchApp.fetch(url, {
headers: { authorization: "Bearer " + token },
}).getContent();
const base64 = Utilities.base64Encode(bytes);
const description = getResFromImage_({
token,
text: "What is this image? Explain within 50 words.",
mime_type: "image/png",
data: base64,
});
console.log(description);
if (description == "No response.") continue;
requests.push({
parent: documentResourceName,
chunk: {
data: { stringValue: description.trim() },
customMetadata: [
{ key: "fileId", stringValue: fileId },
{ key: "url", stringValue: file.getUrl() },
],
},
});
}
if (requests.length == 0) return;
// 2. Put descriptions to document as chunks.
const res = CorporaApp.setChunks(documentResourceName, { requests });
console.log(JSON.stringify(res.map((r) => JSON.parse(r.getContentText()))));
}
When this script is run, a corpus and a document are created. And, the descriptions of the images in the folder are created by Gemini API. And then, the description is put into a document. This document is used in the following scripts.
Sample 1: For templates of Document
Before you use this script, please prepare a Google Document including a template as follows.

The sample script is as follows. Please set the Google Document ID of your Google Document to documentId. When you run the above script, documentResourceName is corpora/sample-corpus/documents/sample-document.
function semanticSearch_withDocuments() {
const documentId = "###"; // Please set your Google Document ID.
const documentResourceName =
"corpora/sample-corpus/documents/sample-document";
const body = DocumentApp.openById(documentId).getBody();
const table = body.getTables()[0];
for (let r = 1; r < table.getNumRows(); r++) {
const a = table.getCell(r, 0);
const searchText = a.getText().trim();
console.log(searchText);
const res = CorporaApp.searchQueryFromDocument(documentResourceName, {
query: searchText,
resultsCount: 1,
});
const { relevantChunks } = JSON.parse(res.getContentText());
if (!relevantChunks || relevantChunks.length == 0) return;
const { data, customMetadata } = relevantChunks[0].chunk;
console.log(data.stringValue);
const fileId = customMetadata.find(({ key }) => key == "fileId");
const blob = DriveApp.getFileById(fileId.stringValue).getBlob();
a.appendImage(blob)
.setWidth(100)
.setHeight(100)
.getParent()
.asParagraph()
.setAlignment(DocumentApp.HorizontalAlignment.CENTER);
a.getChild(0).removeFromParent();
table.getCell(r, 1).setText(data.stringValue);
}
}
When this script is run to the above template Document, the following result is obtained. By the way, in this case, it seems that the text of a placeholder like {{###}} can be directly used as a search text.

Sample 2: For templates of Slide
Before you use this script, please prepare a Google Slide including a template as follows.

The sample script is as follows. Please set the Google Slide ID of your Google Slide to presentationId. When you run the above script, documentResourceName is corpora/sample-corpus/documents/sample-document.
function semanticSearch_withSlides() {
const presentationId = "###"; // Please set your Google Slide ID.
const documentResourceName =
"corpora/sample-corpus/documents/sample-document";
const s = SlidesApp.openById(presentationId);
const slide = s.getSlides()[0];
slide.getShapes().forEach((s, i) => {
console.log(`--- Shape ${i + 1}`);
const searchText = s.getText().asString().trim();
console.log(searchText);
const res = CorporaApp.searchQueryFromDocument(documentResourceName, {
query: searchText,
resultsCount: 1,
});
const { relevantChunks } = JSON.parse(res.getContentText());
if (!relevantChunks || relevantChunks.length == 0) return;
const { data, customMetadata } = relevantChunks[0].chunk;
console.log(data.stringValue);
const fileId = customMetadata.find(({ key }) => key == "fileId");
const blob = DriveApp.getFileById(fileId.stringValue).getBlob();
s.replaceWithImage(blob);
});
}
When this script is run to the above template Slide, the following result is obtained.
Note:
- When you have already had the required image stocks, I think that this method will be useful with the low process cost because the embedding from the description has already been created in the corpus.
- I believe that shortly, Gemini API will be able to also create an image and the process cost will be reduced. At that time, I thought that the above method could be achieved without using the image stocks.