Abstract
Gemini excels at text generation with RAG for large datasets, but smaller ones benefit from prompting or data upload. This report explores using Gemini 1.5 Flash/Pro with RAG on medium-sized, Google Spreadsheet-stored datasets for improved accuracy and effectiveness.
Introduction
Gemini’s text generation capabilities have seen significant advancements with the Retrieval-Augmented Generation (RAG). This approach excels for large datasets, where embedding data and querying the model leads to high-quality answers. However, for smaller datasets, directly including data in the prompt or an uploaded file can be more efficient. Ref
A recent request asked for content generation using both Gemini 1.5 Flash and Retrieval Augmented Generation (RAG) at a low cost. The RAG component would use a Q&A dataset of approximately 100,000 items. To accommodate this, I considered using a Google Spreadsheet-managed corpus instead of a single data file containing all Q&A datasets. I anticipated future growth in the Q&A dataset. While Gemini offers semantic retrieval through the ‘models.generateAnswer’ function, it primarily relies on the ‘models/aqa’ model. Although functional, this model might have limitations in response diversity and update frequency compared to the more versatile Gemini 1.5 Flash and Gemini 1.5 Pro models.
This report explores strategies to address these limitations and achieve high-quality content generation using Gemini 1.5 Flash and Gemini 1.5 Pro models. We will leverage RAG techniques and optimize the use of corpus data stored in Google Spreadsheets. These efforts aim to improve the overall accuracy and effectiveness of Gemini’s text generation capabilities, specifically for situations involving medium-sized datasets.
Repository
The repository of this application is https://github.com/tanaikech/QAApp.
When you want to see the scripts of this report, you can do it in my repository.
Workflow
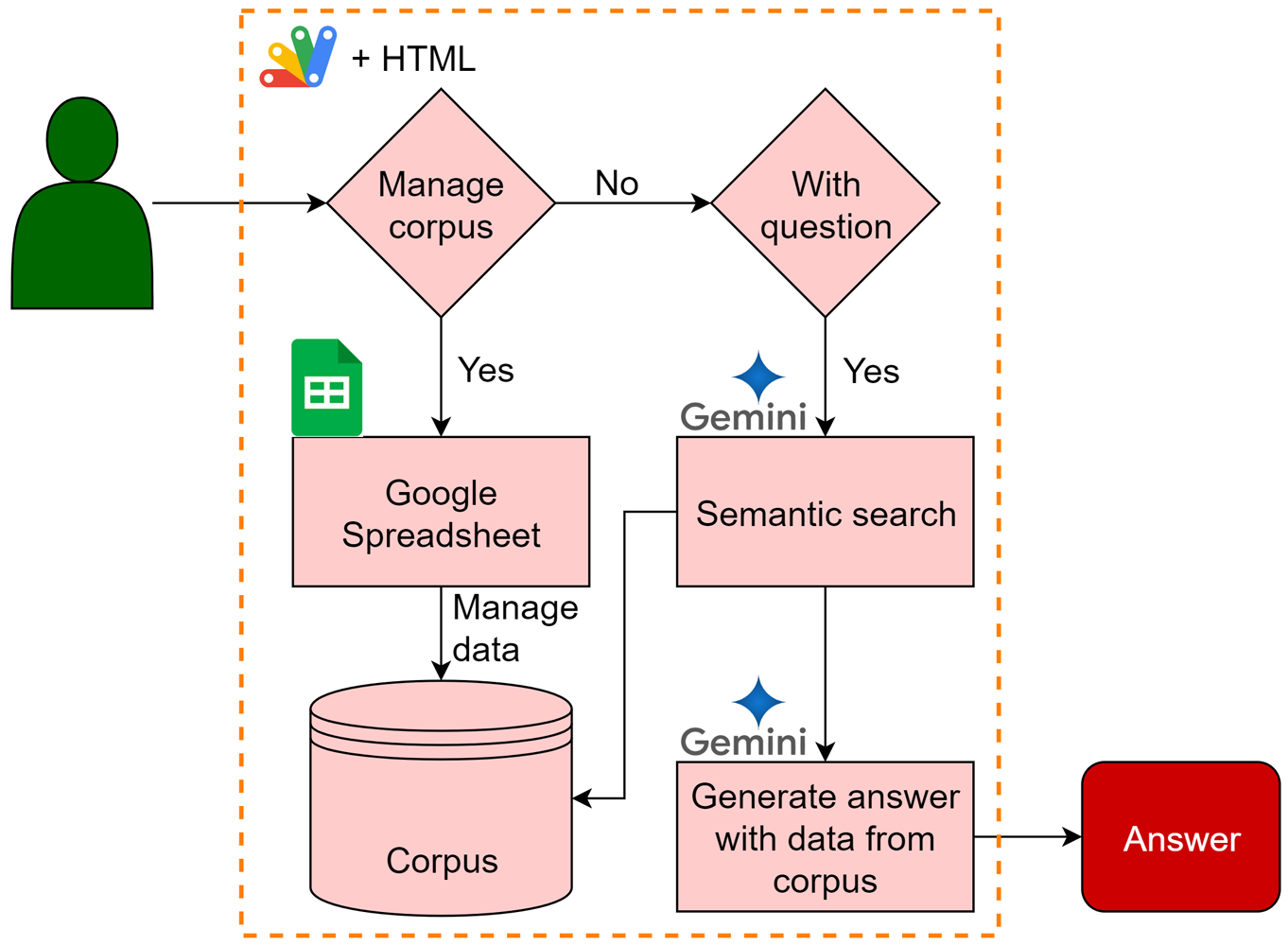
Process for managing corpus
- Data: Read data from Google Spreadsheet.
- Divide data into chunks: Break down the data into smaller segments (chunks) and store them in a document within the corpus. In this case, each chunk is created every row.
Process for generating an answer
- Retrieve relevant chunks: Use the “corpora.documents.query” method to retrieve chunks that meet the specified threshold criteria.
- Upload chunks to Gemini: Upload the selected chunks to Gemini as a file.
- Generate content: Employ the Gemini 1.5 Flash and Gemini 1.5 Pro models to generate content based on the prompt and the uploaded file.
For application
In this report, to implement the aforementioned goal in a practical application, I utilized a Google Spreadsheet and Google Apps Script.
Usage
1. Copy a Google Spreadsheet
When you test this application, you can do it by copying the following Google Spreadsheet. After you copy the Spreadsheet into your Google Drive, you can do the following steps.
You can copy the Spreadsheet to your Google Drive by accessing the following URL.
https://docs.google.com/spreadsheets/d/1zhq82EbhJXBYyYM9t97ixwxiXCc5wDk8Ytl1mUrXUEs/copy
When you open this Spreadsheet, you can see the following 2 sheets.
dashboard: This sheet is used for setting variables including the API key for using Gemini API and corpus name.data: This sheet is used for managing chunks in the corpus.
This spreadsheet has a container-bound script including 5 script files, 1 HTML file, and 1 JSON file.
appsscript.json: Manifest file.Code.gs: Main functions.CorporaApp.gs: https://github.com/tanaikech/CorporaAppGeminiWithFiles.gs: https://github.com/tanaikech/GeminiWithFilesQAApp.gs: Main class object. https://github.com/tanaikech/QAAppjavascript.gs: Javascript for HTML.index.html: HTML for user interface.
2. Linking Google Cloud Platform Project to Google Apps Script Project
In this case, you can see how to do this at my repository. Please link your Google Cloud Platform Project with the container-bound script of the copied Spreadsheet.
Also, please enable 2 APIs Generative Language API and Sheets API at the API console.
3. Set “dashboard” sheet
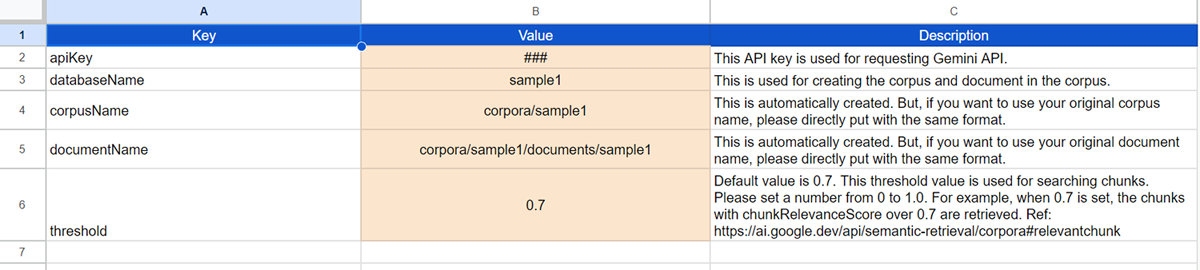
The above image is the “dashboard” sheet. Please set the column “Value” in the dashboard sheet to your situation. At least, please set your API key for using Gemini API. The API is used for uploading a file to Gemini and generating content. The corpus is managed by the access token. So, it is required to link the Google Cloud Platform Project to the Google Apps Script Project.
4. Set “data” sheet
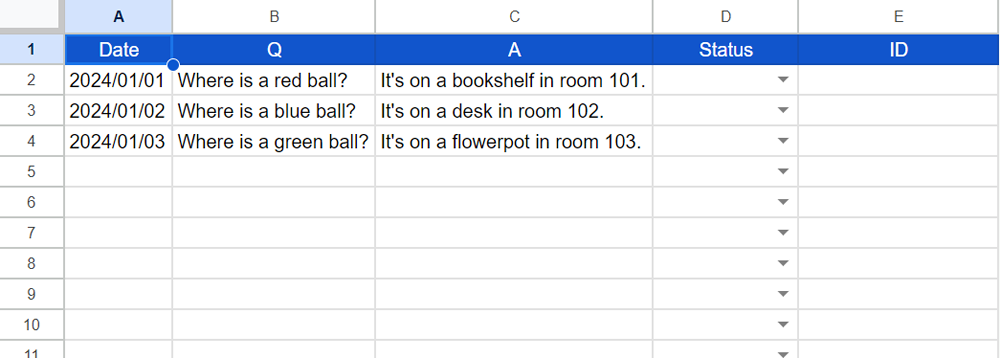
The above image is the “data” sheet. Please set the questions and answers to columns “B” and “C”. Column “D” is used for managing data. Column “E” shows IDs when the data is put into the corpus. Now, these are not required to be used.
After the above setting, this application can be worked.
5. Testing
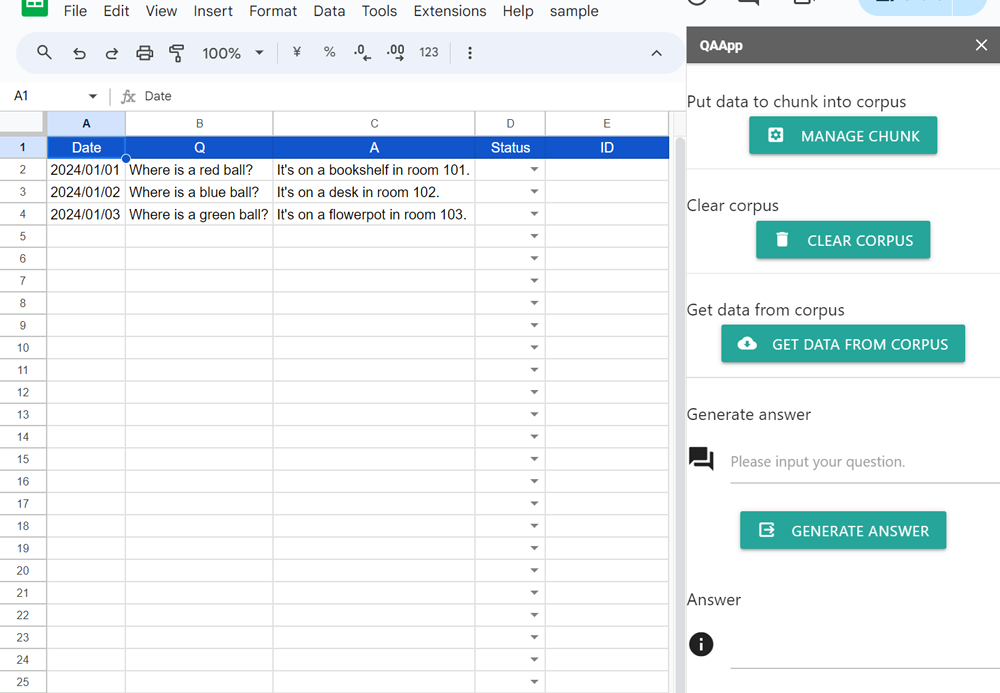
When you run “Open sidebar” from the custom menu, the sidebar is opened as shown in the above image. The demonstration can be seen at the top of this report.
- Open sidebar.
- Put the data into columns “A” to “C”. It supposes that you have already done this.
- Click “MANAGE CHUNK” on the sidebar. By this, the data of columns “A” to “C” are put into corpus. And, each ID on the corpus is automatically put into column “E”.
- Put your question into the text box of “Generate answer”.
- Click “GENERATE ANSWER”. By this, the answer is generated by Gemini with your data.
If you want to update data, please do the following steps.
- Modify columns “B” and “C” and set column “D” to “Update”.
- Click “MANAGE CHUNK” on the sidebar.
If you want to delete several pieces of data, please do the following steps.
- Set column “D” to “Delete”.
- Click “MANAGE CHUNK” on the sidebar.
If you want to clear all data in the corpus, please do the following steps.
- Click “CLEAR CORPUS” on the sidebar.
If you want to load data from the existing corpus, please do the following steps.
- Set “databaseName”, “corpusName”, and “documentName” in the “dashboard” sheet. Here, please set the name of the existing corpus and document.
- Click “GET DATA FROM CORPUS”. By this, the data is loaded from your corpus and put into the “data” sheet. In this case, the data is overwritten in the sheet. Please be careful about this.
You can also see the whole script at my repository.
Summary
This report details a method to improve Gemini’s text generation accuracy with medium-sized datasets using Google Spreadsheet as a Retrieval-Augmented Generation (RAG) corpus. Instead of relying solely on the ‘models/aqa’ model, this approach leverages Gemini 1.5 Flash/Pro models for increased response diversity and update frequency. Data from the spreadsheet is divided into chunks and stored within a Google Cloud Platform corpus. A Google Apps Script facilitates data management and content generation. This allows for dynamic, accurate responses to user queries based on the information stored in the spreadsheet.